Problem statement
The ongoing management of data quality poses significant challenges within a big data environment, particularly when relying on human intervention. The sheer volume, velocity, and variety of data generated in such environments make it increasingly difficult for human resources to maintain data accuracy, consistency, and reliability. Some of the current issues in human management of data quality within a big data environment include:
Choice of open source tooling
In response to the challenges faced in managing data quality within a big data environment, the open-source community has developed a range of tools to assist organisations. These open-source data quality tools provide cost-effective alternatives to proprietary solutions and offer functionalities that address various data quality aspects. Some examples of popular open-source data quality tools:
Each solution has their own pro’s and cons, but in reality – it shouldn’t actually matter which tooling is required – the use of AI for template code generation can provide an abstraction to the data engineering team and their preferred framework
The use of AI to support
Artificial Intelligence (AI) has the potential to revolutionise data quality management within a big data environment by augmenting human capabilities. One significant application of AI is its ability to generate code against any target framework with a standardised input. By leveraging AI techniques such as machine learning and natural language processing, organisations can automate the generation of code snippets or scripts that improve data quality processes.
AI-driven code generation significantly accelerates and streamlines data quality tasks. Reducing the cost of achieving data quality controls and also the human limitations in producing this at scale.
How bigspark leverage AI and open source tooling for data governance
Our CTO Chris Finlayson explains: “AI is not often considered for data governance use cases, more often viewed as a data governance challenge! It has been interesting to explore the contrarian position and the results have been compelling. With the support of Large Language Models (LLM), our engineering team is able to consistently generate high quality pipelines for data quality measurement – based only on provided schema metadata, minimal annotation and natural language inputs. We believe that AI can provide massive acceleration within the data governance research space and are excited to be innovating in this”
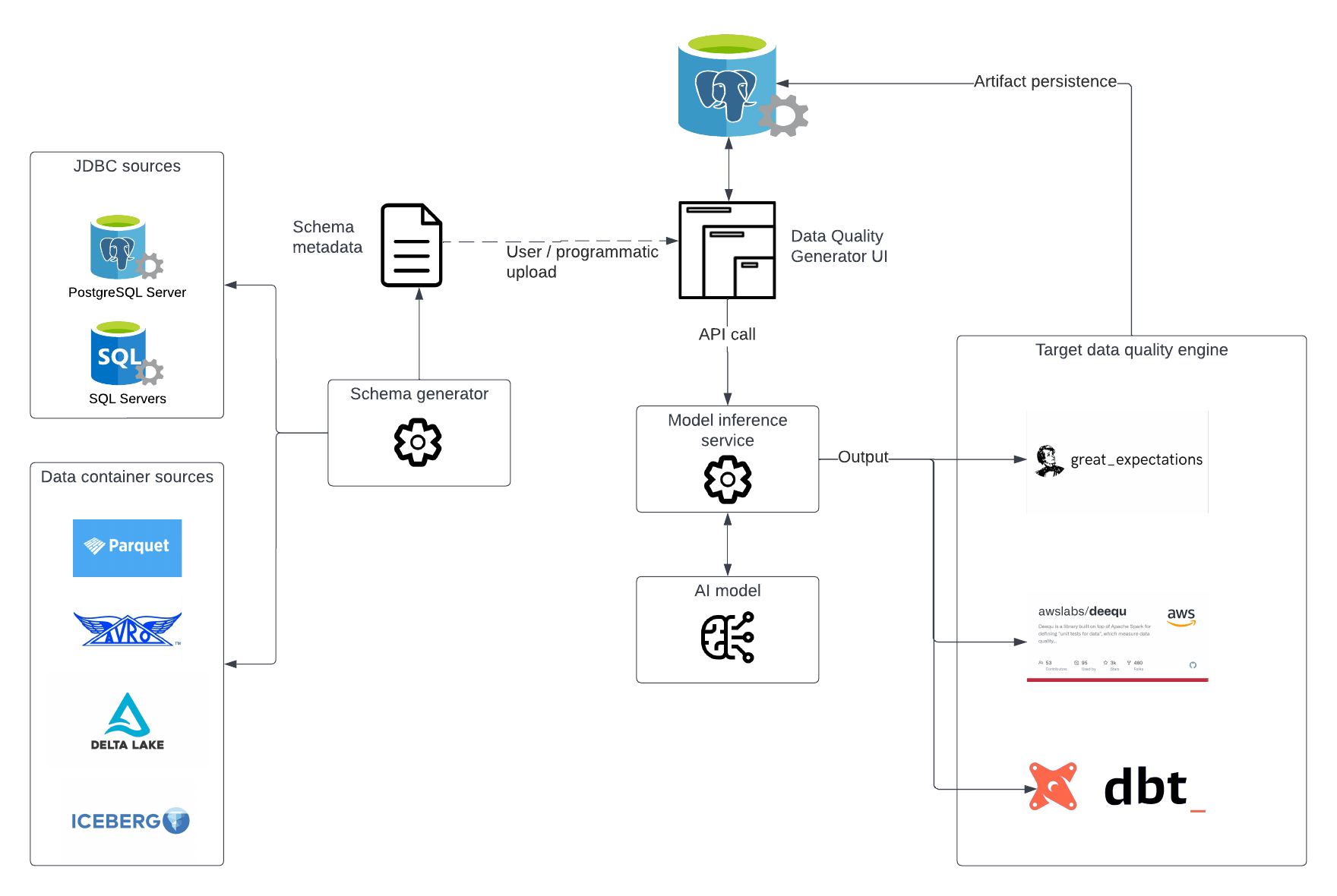
Our AI Data Quality solution
In this overall solution, we demonstrate how we can extract schema from any common source format, generate an consistent metadata markup file, supply into an inference service via a user interface and generate data quality pipelines against the desired framework.
For example – Generated code artifacts can be compiled against Amazon deequ and deployed into a dedicated data quality orchestration
How bigspark can accelerate your data quality deliverables
Please contact us with the form below to arrange a discussion and detailed review of the solution!
